
Albion Stats Website
In the summer of 2020 I started playing an MMORPG called Albion Online with some friends during the pandemic. It's a pretty unique game that has "full-loot" combat, this means that when you kill another player you can take all of their things. Conversely, when you are killed you lose everything you were carrying.
When you're new, you mostly stick to the safe areas and try to build up your skills and your bank. Getting your first kill when you're new is a big deal. The adrenalin rush that comes with the fear of losing every thing you've spent hours to buy is very powerful. Even after hundreds of kills, Albion can get my blood pumping like no other game I've ever played.
Since these kills, especially the ones that happen in the open world are so memorable, it's natural to want to see a history of them. The game devs offer a killboard website, but it leaves a lot to be desired. It only shows you recent events and it is painfully slow most of the time. There were a few other 3rd party stats websites, but they were not the most reliable either.
Enter Murder Ledger, my attempt at a 3rd party killboard and stats websites.
At the start, my primary goal was to provide a fast, searchable, and complete history of every player's kills and deaths.
Screenshots🔗
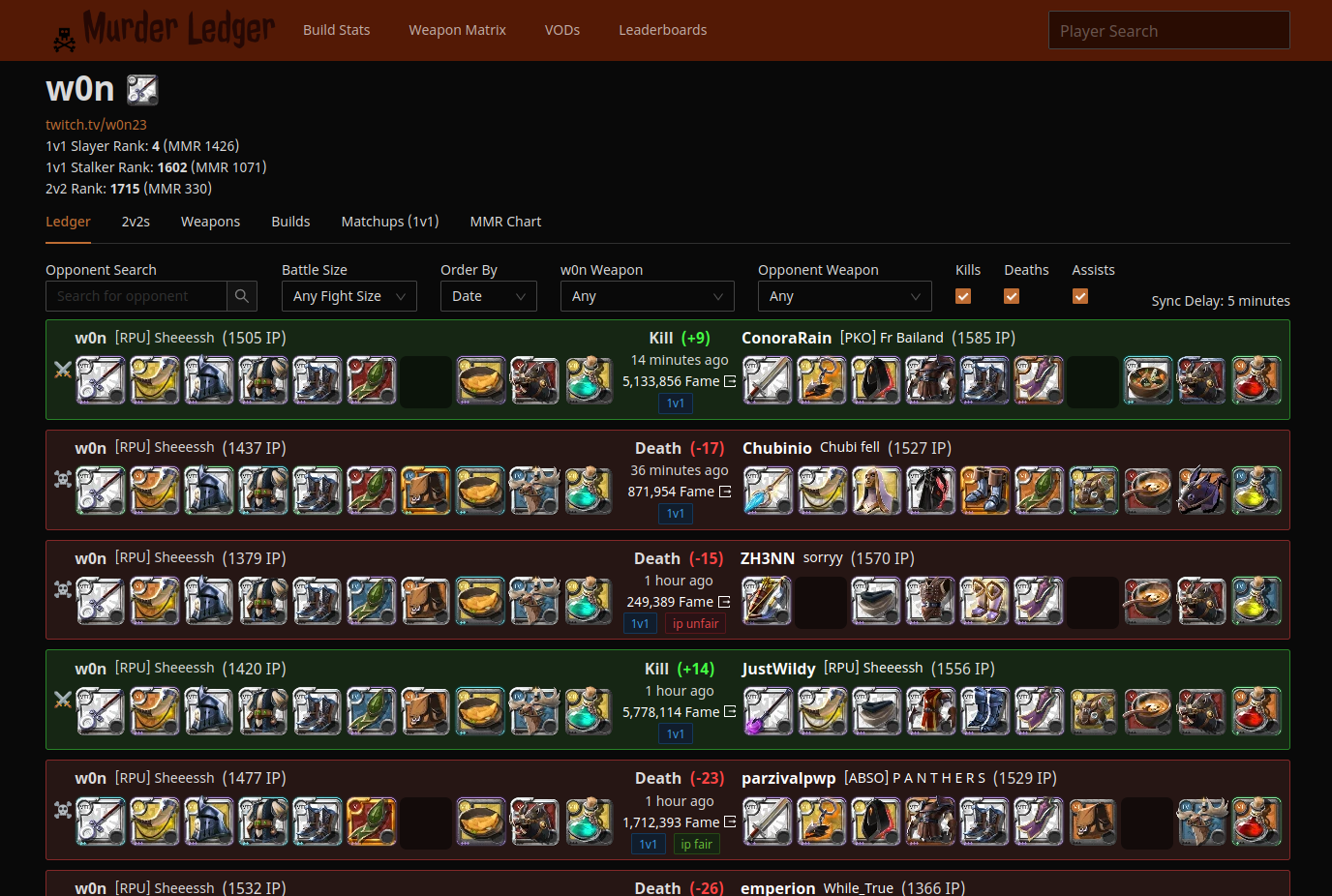



Architecture🔗
The application has four major components.
Event Fetcher🔗
The public API from the first party killboard doesn't serve all events with infinite pagination. Instead, there's a recent events endpoint which holds only the last 1000 events and new events are pushed on every couple of minutes. This endpoint supports pagination with a maximum page size of 50.
The event fetcher's job is to poll this endpoint. The basic idea is just to request the first couple of pages every 30 seconds or so. If we find that the "saturation" of new events is high in the first three pages, then we'll do a full fetch to request all 1000 recent events. Sometimes, when the game has very high player activity more than 1000 events may get dumped at one time. This is referred to as 100% saturation and it will trigger an alert in sentry.io, but there's not much that we can do about it.
The fetcher just transfers these the JSON data of these events into a Kafka log. It uses an LRU cache to keep track of the recent event IDs that it has seen to avoid queueing the same event many times. When we poll the recent events, we'll get some events which we already pulled previously. The consumer of the log is resilient to this, but the LRU helps ensure that most of the space used by the Kafka log is not filled with duplicates.
Event Persister🔗
All of these events that we're collecting and stuffing into Kafka aren't going to process themselves. They need to be processed and saved into a database for use by the application. This is the job of the event persister. It's primary purpose is to transform the events into a more compact format so that we only keep the parts we care about and save them. There's also a crude processing pipeline that handles things like ranked elo (rating) transactions or linking the event to a twitch stream VOD if the player was live streaming.
I chose MySQL, a boring but reliable relation database to store the events. A relational DB is ideal for this use case, since we want to perform joins and calculate stats while keeping a sustainable data footprint.
Collecting all events every day is a pretty significant amount of data. There
are 120000 to 150000 events every day that need to be processed and saved. I
want murderledger to be able to scale sustainably for many years. One technique
to help minimize the storage was to essentially take a hash of the player's
equipment and use that as the primary key in the loadouts table. This helps a
ton since one player may get many kills and deaths wearing the exact same gear.
There are also "meta" builds, so at any given time the majority of players are
using the same builds.
One of the most valuable features of murderledger turned out to be integration with twith.tv. On a whim, I decided to look into using the twitch API to see if we could essentially get clips of recent fights which were live streamed. The process involves manually linking a streamers twitch channel to their Albion player name. Then when we see an event for a player that has a linked twitch channel, we use the twitch API to check if they are live. If they are, and they have VODs enabled, then we can generate a link to the twitch video with a timestamp offset to right around the time the kill happened. This feature was a game changer. Murderledger lets players find videos of specific weapon matchups to see how other people play and how they can improve. It also helps content creators easily find the timestamps of specific fights in their VODs.
Web API🔗
Now that the required data is in-place, it's possible to implement our own API endpoints to page through a players events or pull any kind of cool stats that we can dream up. The web API is a very straight-forward rest/json design. It uses a gin and a really nifty plugin called fizz which helps you generate an OpenAPI spec directly from the endpoint code. This was important to me, because even though I don't intend murderledger's API to be strictly versioned and managed as a public API, I do want other developers to be able to use the API to build cool things like twitch extensions or discord bots. Generating an OpenAPI spec allows other people to easily use the API without having to inspect my website to figure out what endpoints are available and how they work. You can browse the spec in Swagger Editor here: https://editor.swagger.io/?url=https://murderledger.com/api/openapi.json
The most difficult and important endpoint to optimize was the player events list. It offers many different filters which complicate the issue. I opted for a design that allows the endpoint to be super fast with the defaults, but if you use some filter on the opponents weapon type for example, then we'll accept a few seconds of latency.
There are also stats queries that are super slow. One of the main features of the site is the stats for the most frequently used builds in 1v1 fights. This are updated nightly and are calculated over the last 7 days. I used k8s cron jobs to schedule several SQL queries which pull the data and insert it into a stats table. It's a sort of very basic "ETL" kind of process. This allows us to serve stats super fast from the API.
Some of the other stats, like the weapon matrix are not calculated by a nightly job, but the API server does keep an in memory cache that's refreshed only when the data is requested, but the cache is more than 12 hours load. A similar strategy is used for the front page, but with a much more frequent update.
Since all of the traffic can be handled by one web server and I don't push updates that require a restart very often, an in-memory cache works great.
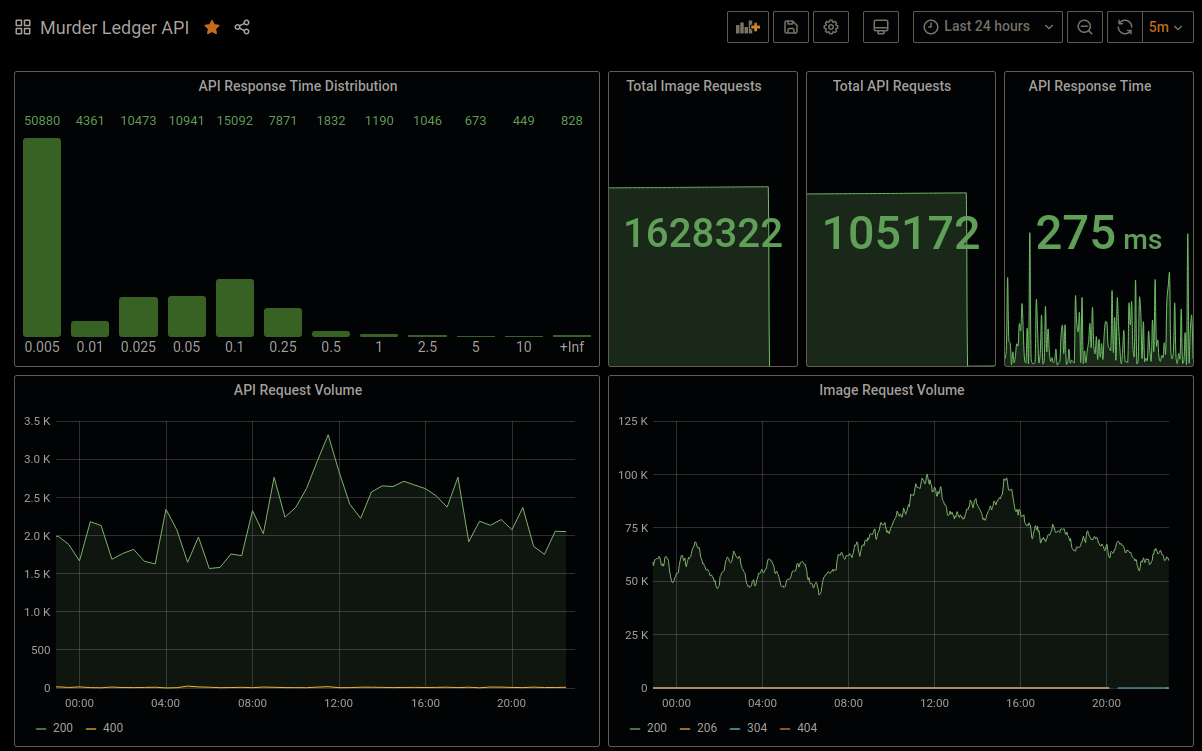
Speaking of traffic, at the time of writing, the API handles about 100K requests per day. Google AdSense claims about 120K ad sessions per month. I'm happy with how well the API has scaled given that it uses a simple/naive design without too much thought put into scaling.
Web App🔗
I originally wrote the front-end in Elm which will always be near and dear to my heart. Unfortunately scaling an Elm app can be a bit painful and I was still learning. Since this project already had a lot of moving parts, I decided it would be best to switch to React and use the Ant Design component library instead. Elm has certain strengths, and it makes some parts of the work absolutely delightful, it really has some big weaknesses that translate to slow development time. Every new page that must be added grows the state monstrosity that must be carefully sliced and managed.
There's not too much else to say about the react app. It does its job, but it's probably the least interesting part of the project.